

How To Filter Outliers In A Data Set
Ways to Detect and Remove the Outliers

While working on a Information Science project, what is it, that you expect for? What is the nigh important function of the EDA stage? There are sure things which, if are non done in the EDA phase, can touch further statistical/Machine Learning modelling. One of them is finding "Outliers". In this post nosotros will try to empathize what is an outlier? Why is it important to place the outliers? What are the methods to outliers? Don't worry, we won't just go through the theory part merely we will exercise some coding and plotting of the data likewise.
Meet the Outlier
Wikipedia definition,
In statistics, an outlier is an observation betoken that is afar from other observations.
The higher up definition suggests that outlier is something which is separate/dissimilar from the crowd. A lot of motivation videos advise to be different from the oversupply, particularly Malcolm Gladwell. In respect to statistics, is it too a expert thing or not? we are going to find that through this mail.
Data Collection & Outliers
Every bit nosotros now know what is an outlier, but, are yous also wondering how did an outlier introduce to the population?
The Data Science projection starts with collection of data and that'due south when outliers first introduced to the population. Though, you will non know near the outliers at all in the collection phase. The outliers can be a result of a mistake during information collection or it can be just an indication of variance in your information.
Allow's have a expect at some examples. Suppose yous have been asked to observe the operation of Indian cricket squad i.e Run made past each actor and collect the data.
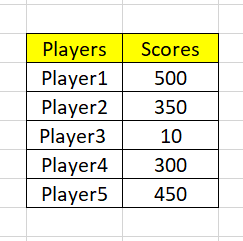
As you tin can see from the to a higher place collected data that all other players scored 300+ except Player3 who scored 10. This figure tin be just a typing mistake or it is showing the variance in your data and indicating that Player3 is performing very bad so, needs improvements.
Now that we know outliers tin can either be a mistake or just variance, how would you decide if they are important or not. Well, it is pretty simple if they are the result of a fault, then we can ignore them, but if it is just a variance in the information we would need think a scrap farther. Before we effort to sympathize whether to ignore the outliers or not, nosotros demand to know the ways to identify them.
Finding Outliers
Most of y'all might be thinking, Oh! I can just have a peak of information discover the outliers merely like we did in the previously mentioned cricket example. Let'due south recall about a file with 500+ column and 10k+ rows, do you lot still recall outlier can exist found manually? To ease the discovery of outliers, we accept plenty of methods in statistics, but we will only exist discussing few of them. Mostly we will try to see visualization methods(easiest ones) rather mathematical.
Then, Let'southward become start. We will exist using Boston Business firm Pricing Dataset which is included in the sklearn dataset API. Nosotros will load the dataset and separate out the features and targets.
boston = load_boston()
10 = boston.information
y = boston.target
columns = boston.feature_names #create the dataframe
boston_df = pd.DataFrame(boston.data)
boston_df.columns = columns
boston_df.caput()
Features/independent variable will be used to look for whatever outlier. Looking at the data above, information technology due south seems, we merely have numeric values i.e. we don't demand to do any data formatting.(Sigh!)
In that location are 2 types of assay nosotros will follow to find the outliers- Uni-variate(one variable outlier assay) and Multi-variate(two or more variable outlier analysis). Don't get confused right, when y'all will start coding and plotting the information, you will see yourself that how easy it was to detect the outlier. To keep things simple, we will start with the basic method of detecting outliers and slowly move on to the advance methods.
Find outliers with visualization tools
Box plot-
Wikipedia Definition,
In descriptive statistics, a box plot is a method for graphically depicting groups of numerical data through their quartiles. Box plots may also take lines extending vertically from the boxes (whiskers) indicating variability exterior the upper and lower quartiles, hence the terms box-and-whisker plot and box-and-whisker diagram. Outliers may be plotted every bit individual points.
Higher up definition suggests, that if in that location is an outlier it will plotted as indicate in boxplot just other population will be grouped together and brandish equally boxes. Let's try and run into it ourselves.
import seaborn as sns
sns.boxplot(x=boston_df['DIS']) 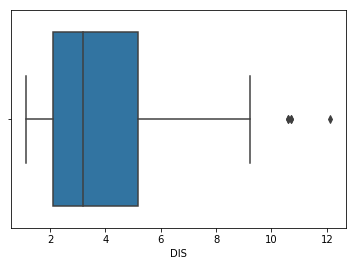
Above plot shows three points between 10 to 12, these are outliers equally there are not included in the box of other observation i.east no where near the quartiles.
Here we analysed Uni-variate outlier i.e. we used DIS cavalcade but to check the outlier. Merely we tin can practice multivariate outlier analysis too. Can we do the multivariate assay with Box plot? Well it depends, if yous accept a categorical values and then you tin can use that with any continuous variable and do multivariate outlier analysis. As we do not have categorical value in our Boston Housing dataset, we might demand to forget nigh using box plot for multivariate outlier analysis.
Besprinkle plot-
Wikipedia Defintion
A scatter plot , is a type of plot or mathematical diagram using Cartesian coordinates to display values for typically ii variables for a fix of information. The information are displayed every bit a collection of points, each having the value of one variable determining the position on the horizontal centrality and the value of the other variable determining the position on the vertical axis.
As the definition suggests, the scatter plot is the collection of points that shows values for 2 variables. We can try and depict scatter plot for 2 variables from our housing dataset.
fig, ax = plt.subplots(figsize=(16,8))
ax.besprinkle(boston_df['INDUS'], boston_df['Revenue enhancement'])
ax.set_xlabel('Proportion of non-retail concern acres per town')
ax.set_ylabel('Full-value property-tax rate per $x,000')
plt.show() 
Looking at the plot to a higher place, we tin most of data points are lying bottom left side only there are points which are far from the population like elevation correct corner.
Notice outliers with mathematical function
Z-Score-
Wikipedia Definition
The Z-score is the signed number of standard deviations by which the value of an observation or data point is above the mean value of what is being observed or measured.
The intuition behind Z-score is to depict any data point by finding their human relationship with the Standard Deviation and Mean of the group of information points. Z-score is finding the distribution of information where hateful is 0 and standard departure is 1 i.due east. normal distribution.
You must be wondering that, how does this aid in identifying the outliers? Well, while calculating the Z-score we re-scale and center the data and look for data points which are too far from zilch. These data points which are way too far from zero will be treated as the outliers. In most of the cases a threshold of three or -iii is used i.e if the Z-score value is greater than or less than 3 or -3 respectively, that information bespeak will exist identified as outliers.
Nosotros will employ Z-score function divers in scipy library to detect the outliers.
from scipy import stats
import numpy as np z = np.abs(stats.zscore(boston_df))
print(z)

Looking the lawmaking and the output to a higher place, it is hard to say which data indicate is an outlier. Let's endeavour and define a threshold to identify an outlier.
threshold = iii
print(np.where(z > 3)) This will give a result as below -

Don't exist dislocated by the results. The first array contains the list of row numbers and second array respective cavalcade numbers, which mean z[55][1] have a Z-score higher than three.
print(z[55][1]) 3.375038763517309
Then, the information bespeak — 55th record on column ZN is an outlier.
IQR score -
Box plot utilise the IQR method to display data and outliers(shape of the data) but in social club to be get a listing of identified outlier, we will demand to use the mathematical formula and recollect the outlier data.
Wikipedia Definition
The interquartile range (IQR), also called the midspread or middle l%, or technically H-spread, is a measure of statistical dispersion, being equal to the difference between 75th and 25th percentiles, or between upper and lower quartiles, IQR = Q3 − Q1.
In other words, the IQR is the first quartile subtracted from the tertiary quartile; these quartiles can be clearly seen on a box plot on the data.
It is a measure of the dispersion similar to standard deviation or variance, merely is much more than robust against outliers.
IQR is somewhat similar to Z-score in terms of finding the distribution of data and then keeping some threshold to identify the outlier.
Let'south find out we can box plot uses IQR and how we can utilize information technology to find the list of outliers as we did using Z-score calculation. Starting time we will summate IQR,
Q1 = boston_df_o1.quantile(0.25)
Q3 = boston_df_o1.quantile(0.75)
IQR = Q3 - Q1
impress(IQR) Here we volition get IQR for each column.
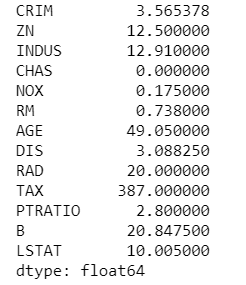
Every bit nosotros now take the IQR scores, it's fourth dimension to get hold on outliers. The beneath lawmaking will give an output with some true and imitation values. The data bespeak where we have Faux that means these values are valid whereas Truthful indicates presence of an outlier.
impress(boston_df_o1 < (Q1 - one.five * IQR)) |(boston_df_o1 > (Q3 + one.5 * IQR)) 
At present that we know how to detect the outliers, it is of import to sympathise if they needs to be removed or corrected. In the next section nosotros will consider a few methods of removing the outliers and if required imputing new values.
Working with Outliers: Correcting, Removing
During data analysis when yous observe the outlier i of most difficult decision could exist how one should deal with the outlier. Should they remove them or correct them? Earlier we talk virtually this, we will have a look at few methods of removing the outliers.
Z-Score
In the previous section, we saw how one can detect the outlier using Z-score but at present nosotros want to remove or filter the outliers and go the clean information. This can be washed with simply one line lawmaking every bit we have already calculated the Z-score.
boston_df_o = boston_df_o[(z < iii).all(axis=1)] 
So, in a higher place code removed around 90+ rows from the dataset i.east. outliers have been removed.
IQR Score -
Just like Z-score we tin can use previously calculated IQR score to filter out the outliers by keeping simply valid values.
boston_df_out = boston_df_o1[~((boston_df_o1 < (Q1 - 1.5 * IQR)) |(boston_df_o1 > (Q3 + i.5 * IQR))).any(axis=ane)] boston_df_out.shape
The in a higher place lawmaking will remove the outliers from the dataset.
There are multiple ways to observe and remove the outliers but the methods, we have used for this exercise, are widely used and piece of cake to understand.
Whether an outlier should be removed or not. Every data analyst/data scientist might go these thoughts in one case in every problem they are working on. I take found some skilful explanations -
https://www.researchgate.net/mail service/When_is_it_justifiable_to_exclude_outlier_data_points_from_statistical_analyses
https://www.researchgate.net/post/Which_is_the_best_method_for_removing_outliers_in_a_data_set
https://www.theanalysisfactor.com/outliers-to-drib-or-not-to-drop/
To summarize their explanation- bad data, wrong calculation, these can exist identified as Outliers and should be dropped but at the aforementioned time you might want to correct them too, every bit they modify the level of data i.e. mean which cause problems when you model your data. For ex- five people become bacon of 10K, 20K, 30K, 40K and 50K and all of a sudden ane of the person first getting salary of 100K. Consider this situation as, you are the employer, the new salary update might be seen as biased and you might need to increase other employee's salary too, to go on the balance. So, there can exist multiple reasons yous want to understand and correct the outliers.
Summary
Throughout this exercise we saw how in data assay phase one can encounter with some unusual data i.e outlier. We learned nearly techniques which tin can be used to find and remove those outliers. But there was a question raised about assuring if it is okay to remove the outliers. To answer those questions we have found further readings(this links are mentioned in the previous section). Promise this post helped the readers in knowing Outliers.
Note- For this exercise, below tools and libaries were used.
Framework- Jupyter Notebook, Language- Python, Libraries- sklearn library, Numpy, Panda and Scipy, Plot Lib- Seaborn and Matplot.
Refernces
- Boston Dataset
- Github Repo
- KDNuggets outliers
- Detect outliers

How To Filter Outliers In A Data Set,
Source: https://towardsdatascience.com/ways-to-detect-and-remove-the-outliers-404d16608dba
Posted by: tharpsandint.blogspot.com
0 Response to "How To Filter Outliers In A Data Set"
Post a Comment